




Table of contents
El paralelismo no debe confundirse con la concurrencia, aunque es común que así ocurra. El paralelismo se preocupa de analizar como superponer operaciones con el objeto de mejorar el rendimiento al realizar una tarea concreta.
Normalmente, un programa lanza un conjunto de subtareas que se ejecutan en paralelo para realizar un trabajo determinado, mientras la tarea principal no continua hasta que todas las subtareas han terminado. El reto desde el punto de vista del paralelismo es determinar las optimizaciones necesarias con respecto a cuestiones tales como la granularidad y el coste de la comunicación.
Sin embargo, la concurrencia es necesaria para implementar el paralelismo. Concretamente, en el ejemplo anterior, se hace cargo de establecer como se definen las distintas tareas, qué características tienen y como se implementan sobre un hardware en concreto. También establece los mecanismos de coordinación y sincronización necesarios para lidiar con la indeterminación, ya que no sabemos cuando terminarán las tareas ni cuando accederán a las estructuras de datos compartidas.
En ese sentido, podemos decir que el paralelismo es una abstracción útil para mejorar el rendimiento de una tarea. Sin embargo, no debe confundirse dicha abstracción con su implementación, que entraría en el campo de la concurrencia. Así, un programa con dos hilos concurrentes que se ejecute en un sistema monoprocesador sin múltiples núcleos ni físicos ni lógicos (SMT) puede ser concurrente pero no paralelo. Obviamente, el paralelismo solo es posible en sistemas multinúcleo, multiprocesador o distribuidos.
A continuación complementaremos lo hablado anteriormente sobre concurrencia considerando que ahora el contexto es el de programas donde pretendemos descomponer y paralelizar tareas limitadas por la CPU.
Multihilo

El uso de múltiples hilos dentro de un programa paralelo es un enfoque muy común. Sin embargo, a diferencia de lo que ocurre en los casos de los que hemos hablado anteriormente, por lo general se crean tantos hilos como núcleos dispone el sistema y se divide entre ellos la tarea que deseamos realizar.
Obviamente, tiene poco sentido crear más hilos que secuencias de instrucciones pueden ejecutarse paralelamente en el sistema.
Agrupamiento de hilos
Como acabamos de comentar, en un problema de programación paralela el número de hilos adecuado viene determinado por el de núcleos, lo que obliga a dividir el problema de manera diferente según las características del hardware donde el programa se va a ejecutar. Esto no es sencillo si la aplicación va a ser distribuida al público y, por lo tanto, será utilizada en ordenadores con características diversas.
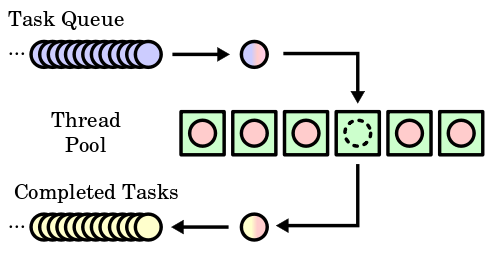
El patrón agrupamiento de hilos comentado en el artículo sobre concurrencia nos puede ayudar a enfrentar este problema. Básicamente, nos permite dividir las tareas limitadas por la CPU tanto como queramos. Y que estas sean ejecutadas sobre un agrupamiento configurado con el mismo número de hilos que núcleos de procesador hay en el sistema donde se está ejecutando la aplicación.
De esta manera, los programas se pueden adaptar al paralelismo del hardware subyacente, aprovechando de forma sencilla las ventajas de los sistemas multinúcleo.
Como ya hemos comentado, las plataformas Java y .NET incorporan una implementación de este patrón. Mientras que para C/C++ existen diversas librerías, entre las que no solo está Qt y su clase QThreadPool, sino que fundamentalmente tenemos que destacar la Threading Building Blocks de Intel (TBB).
Referencias
Concurrence is no parallelism — The Go Blog.
Concurrency pattern — Wikipedia.
Thread pool pattern — Wikipedia.