




La concurrencia tiene que ver con manejar múltiples eventos que se superponen en el tiempo fuera del control del programa. Por lo tanto debe preocuparse de manejar la creciente complejidad que surge de la necesidad de un control de flujo no determinista. Los programas concurrentes vienen con frecuencia limitados por la E/S, como por ejemplo es el caso de las arañas usadas por los buscadores de Internet para explorar la web. Estos programas inician varias peticiones HTTP para obtener diversas páginas y aceptan de forma concurrente las respuestas con su contenido, acumulándolas en el conjunto de páginas visitadas. El control del flujo es no determinista porque las respuestas no se reciben necesariamente en el mismo orden en el que el programa hizo las correspondientes peticiones.
En general existen aplicaciones que son fundamentalmente concurrentes, como los servidores web, los de archivos, los de base de datos y otros programas similares que deben manejar al mismo tiempo la conexión con diversos clientes. También son concurrentes las aplicaciones paralelas, donde una tarea se descompone en otras más pequeñas que se ejecutan al mismo tiempo para obtener el máximo rendimiento, porque en muchas ocasiones no se sabe de antemano cuando van a terminar estas subtareas o van a intentar acceder a las estructuras de datos compartidas. Así mismo son concurrentes las aplicaciones para las GUI modernas, ya que peticiones tales como atender un click de ratón o actualizar el contenido de una ventana pueden llegar en cualquier momento fuera del control del programa.
Por su naturaleza no determinista, los programas concurrentes son difíciles de depurar.
Manejar la concurrencia
Hasta el momento hemos dejado entrever las dos motivos más comunes por los que necesitamos gestionar la concurrencia:
Si nuestro programa deben manejar eventos externos que escapan a su control, como es el caso de un servidor que deben aceptar peticiones de múltiples clientes o una aplicación interactiva que debe responder ante los eventos notificados por el sistema a causa de las acciones del usuario, necesitamos manejar la concurrencia. Hay que tener en en cuenta que las tareas de estos programas con frecuencia están limitadas por la E/S, aunque no siempre es así. Por ejemplo, los recolectores de basura concurrentes presentes en algunas plataformas (p. ej. Java y .NET) están enteramente limitados por la CPU. Obviamente todo sería mucho más sencillo si optáramos por ignorar la concurrencia, manejando en turno una solicitud cada vez. Pero entonces una petición o un evento bloquearía a los otros hasta que hubiera terminado.
Si en nuestro programa queremos usar programación paralela para descomponer ciertas tareas en otras más pequeñas que se puedan ejecutar al mismo tiempo con el objeto de obtener el máximo rendimiento, también es necesario gestionar la concurrencia. Sin embargo, por lo general, este tipo de tareas están limitadas por la CPU.
En la actualidad existen diferentes maneras de tratar la concurrencia, que pueden ser más o menos convenientes según el tipo de problemas a resolver. Nosotros nos centraremos por el momento en el primer tipo, dejando los detalles relacionados con la programación paralela para un artículo posterior.
Multihilo
El uso de múltiples hilos dentro de un mismo programa es uno de los enfoques más comunes cuando se plantea resolver un problema de concurrencia. En las mayor parte de los sistemas modernos los hilos creados por la aplicación son conocidos y gestionados por el núcleo (modelo uno a uno) lo que les permite acceder simultáneamente al mismo y ser planificados en diferentes procesadores, pudiendo así aprovechar el paralelismo ofrecido por el hardware en los sistemas multiprocesador y/o multinúcleo.
Obviamente la manera en la que se utilizan los hilos dependen del tipo de problema. Si lo que se pretende es gestionar eventos o peticiones externas, lo más habitual es crear un hilo por cliente conectado. Así cada hilo funcionará de manera independiente procesando y atendiendo las peticiones de su cliente.
Características
Las principales características de la programación multihilo son:
Es muy sencilla, ya que permite gestionar diferentes hilos de ejecución dentro del espacio de direcciones virtual de un mismo proceso, lo que facilita la compartición de datos y otros recursos comunes.
Se puede volver muy compleja, debido al cuidadoso control que es necesario hacer sobre el acceso a los recursos compartidos, a poco que el problema crezca.
Modelos basados en paso de mensajes
Debido a que muchos de los problemas de la programación multihilo provienen de la compartición de recursos, se ha extendido el uso de modelos basados en paso de mensajes para resolver problemas concurrentes complejos.
En estos modelos los hilos no acceden directamente a los datos sino que se los transfieren entre si por medio de mensajes. Así se evita compartir recursos y, por tanto, el uso de cerrojos, semáforos y variables de condición. Lamentablemente así se pierde sencillez.
Para estos lenguajes como Scala o Erlang implementan el modelo Actor, mientras que Go se basa en en el modelo CSP. Ambos casos, pese a sus diferencias, fundamentalmente operan tal y como hemos descrito. También entraría dentro de este tipo de modelos el mecanismo de comunicación entre hilos que implementa Qt a través del uso de señales y slots.
Multiproceso
En los sistemas operativos que implementan una llamada al sistema tipo fork se pueden crear de forma sencilla múltiples procesos, en lugar de hilos, para manejar la concurrencia. La forma de hacerlo no difiere mucho de la programación multihilo, aunque es necesario tener en cuenta los siguientes aspectos:
Escala peor, ya que soportar cientos de clientes implica la creación de cientos de procesos y estos son más costosos que los hilos, en lo que respecta al consumo de recursos del sistema.
No es tan sencilla como la programación multihilo, porque hay que indicar explícitamente que regiones de la memoria se desea compartir entre procesos. Además, normalmente sólo se puede establecer que recursos van a ser compartidos durante la creación de cada proceso, no pudiendo compartir otros recursos posteriormente.
Los procesos ofrecen mejor aislamiento que los hilos y por tanto mayor robustez y seguridad.
Respecto a esto último debemos de tener en cuenta que un acceso indebido a la memoria en uno de los procesos, quizás ocasionada por una petición de un cliente mal formateada, no tiene por qué provocar la caída de toda la aplicación; a diferencia de lo que pasaría en una aplicación multihilo. De igual manera, si un atacante tomara el control de uno de los procesos tendría más difícil tener acceso a los otros. Además, los procesos tienen características interesantes de las que carecen los hilos, como la posibilidad de ejecutarse como un usuario concreto del sistema o en un jaula chroot.
Agrupamiento de hilos
Aunque más baratos que los procesos, los hilos tienen un coste que llegado el momento puede hacer que nuestra aplicación no pueda escalar ya que no se puedan crear más hilos.
Para evitarlo se puede hacer uso del patrón agrupamiento de hilos (o thread pool) que básicamente consiste en:
- Crear un grupo de hilos, una cola con las tareas que deben ser ejecutadas en dichos hilos y otra cola donde almacenar los resultados de las tareas ejecutadas.
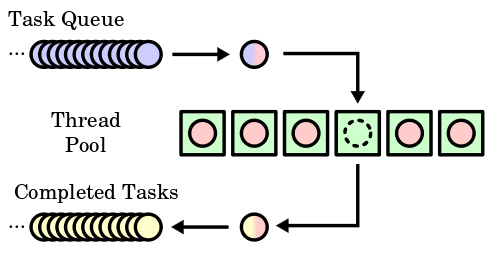
Cada vez que un hilo del agrupamiento queda libre, toma la siguiente tarea de la cola y la ejecuta hasta que es completada, insertando los resultados en la cola correspondiente.
Cuando la cola de tareas está vacía, los hilos pueden morir o dormir hasta que hayan más tareas.
Número de hilos
Obviamente el número concreto de hilos del agrupamiento se debe ajustar con el objeto de conseguir el mayor rendimiento posible. Con tareas limitadas por la E/S el número generalmente depende de la capacidad del sistema y del tipo de tarea, por lo que suele ser necesario determinarlo experimentalmente.
Además, en ocasiones el número de hilos en el agrupamiento puede ser ajustado por el programa dinámicamente, en base al número de tareas pendientes de ser ejecutadas. Así la aplicación podría incorporar hilos al agrupamiento sólo si la cantidad de tareas a la espera supera cierto umbral, y únicamente hasta el máximo por encima del cual hemos determinado que el rendimiento se vería penalizado.
Soporte
Debido a la proliferación de los procesadores multinúcleo, es cada vez más común que los diferentes lenguajes dispongan de alguna implementación del patrón agrupamiento de hilos, ya sea en la librería que lo acompaña o a través de librerías de terceros, con el fin de facilitar la programación paralela.
Plataformas como Java y .NET lo incorporan, así como el sistema operativo Mac OS X bajo el nombre de Grand Central Dispatch (GCD). En el caso de C++ existen múltiples librerías, como por ejemplo Intel TBB, diseñada específicamente para facilitar que los programas aprovechen las ventajas de los sistemas multinúcleo, o Qt, que incorpora su propia implementación del patrón a través de la clase QThreadPool:
class HelloWorldTask : public QRunnable
{
void run()
{
qDebug() << "Hello world from thread"
<< QThread::currentThread();
}
}
HelloWorldTask *hello = new HelloWorldTask();
// QThreadPool toma la propiedad y borra 'hello' automáticamente
QThreadPool::globalInstance()->start(hello);
Aunque es mucho más directo y sencillo utilizar el API de más alto nivel de abstracción QtConcurrent:
QFuture<void> future = QtConcurrent::run([&]() {
qDebug() << "Hello world from thread"
<< QThread::currentThread();
}
Ejecución basada en eventos
Como ya hemos comentado, los hilos tienen un coste que no se puede despreciar cuando el número que necesitamos es alto. Además, en muchos problemas de concurrencia las tareas están muy limitadas por la E/S, por lo que a penas se obtiene beneficio alguno de la posibilidad de ejecutarlas en paralelo. En esos casos la forma de gestionar la concurrencia que se ha demostrado más eficaz es la ejecución basada en eventos.
Simplificando, sus principales características son:
Generalmente sólo se usa un hilo de ejecución. Por tanto no es posible la ejecución paralela de código, lo que implica que si se ejecutan tareas limitadas por la CPU se podría estar bloqueando las peticiones de otros clientes al ocupar el hilo de ejecución.
Toda la E/S es asíncrona, para evitar el bloqueo de las peticiones de los clientes y que las operaciones de E/S se ejecuten en paralelo, tanto entre sí como respecto al código en el hilo de ejecución.
Hace uso de un bucle de mensajes a donde llegan los eventos de E/S notificados por el sistema operativo. Desde este bucle se llama a las rutinas de callback correspondientes, donde la aplicación tiene el código que da respuesta a dichos eventos.
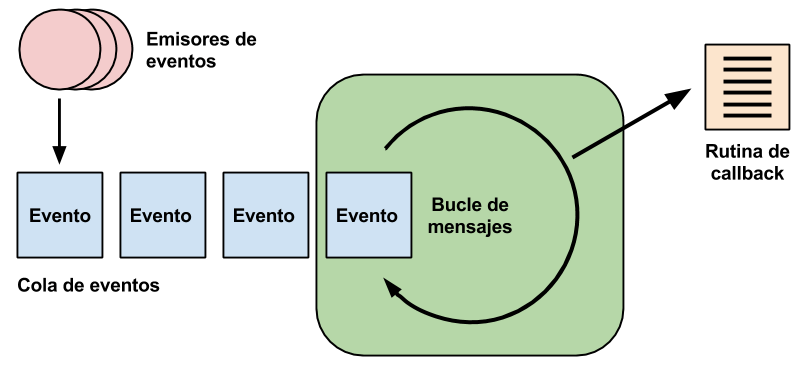
Estas rutinas de callback pueden tener nombres predefinidos, como es el caso del sistema de señales de Qt, o especificarse a través de un argumento adicional indicado cuando se solicitó la E/S.
Por lo general los programas que gestionan la concurrencia de esta manera tiene muchos menos requerimientos de memoria que los que usan múltiples hilos o procesos, lo que les permite escalar mejor. Este es por ejemplo el caso del servidor web Nginx o el servidor de aplicaciones en Javascript Node.js cuando se los compara con Apache, un servidor web que según la configuración utiliza un hilo o un proceso por conexión.
Corrutinas
Aunque eficiente, la ejecución basada en eventos puede ser más compleja de implementar ya que el control del flujo de ejecución se invierte. Es decir, en un patrón procedural normal la interacción se expresa de forma imperativa, haciendo llamadas a procedimientos, funciones o métodos. En su lugar, en la ejecución basada en eventos se especifican las respuestas deseadas a los eventos notificados, siendo imposible desarrollar una función que contenga todo el código implicado en una tarea concreta.
Esto se puede resolver incorporando el uso de corrutinas. Estas son una generalización de los procedimientos o subrutinas convencionales de las que se puede salir por diversos puntos para posteriormente volver y reiniciar la ejecución desde el último punto de retorno.
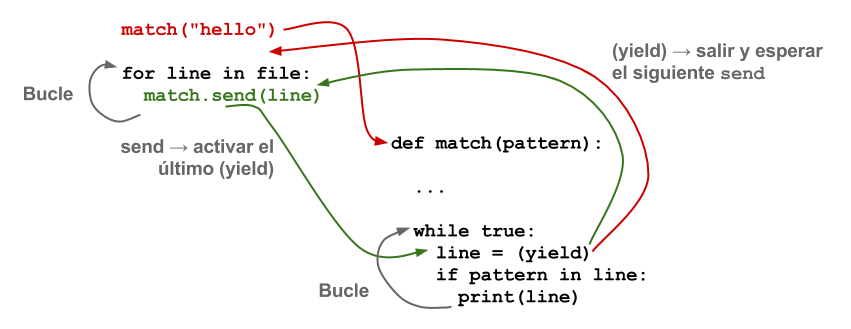
En el contexto de la ejecución basada en eventos, las distintas tareas que deben ser ejecutadas pueden programarse como corrutinas, mientras que las operaciones de E/S, a parte de solicitar la operación correspondiente de manera asíncrona, forzarían la salida de la corrutina. Así el bucle de mensajes, en lugar de invocar el callback de una operación completada, sólo tiene que restablecer la ejecución de la corrutina allí donde fue interrumpida.
Los corrutinas son soportadas por algunos lenguajes de alto nivel como Ruby, Lua o Go. Este último incluso permite planificar su ejecución en paralelo dentro de un agrupamiento de hilos, dando lugar a lo que sus desarrolladores ha denominado goroutines. Otro ejemplo destacable es Python, que tiene su propia solución nativa basada en las sentencias async/await y el módulo de la librería estándar asyncio.
Sin embargo, esta no es la única opción que tienen los desarrolladores de Python:
Existen varios proyectos que han creado sus propias librerías de concurrencia, alternativas al módulo asyncio, para ser usadas también con las sentencias async/await.
Existe una extensión, llamada greenlet, al intérprete de referencia de Python que implementa una solución alternativa propia para el uso de corrutinas en Python.
La misma solución que greenlet existe como un intérprete de Python alternativo llamado Stackless Python. Este intérprete es usado en productos como Eve Online o Second Live, donde el número de conexiones simultáneas es muy alto.
Por lo demás, hasta hace unos años la mayor parte de los lenguajes más populares no soportaban corrutinas, ni en el propio lenguaje ni a través de su librería estándar. Por fortuna, esta tendencia ha cambiado y muchos tienen algún tipo de soporte, aunque sea por medio de una librería externa.
Referencias
Concurrency pattern — Wikipedia
Thread pool pattern — Wikipedia
Coroutine — Wikipedia
The Concurrent Collector — Java SE 6 HotSpot[tm] Virtual Machine Garbage Collection Tuning
A Tale of Two Concurrency Models: Comparing the Go and Erlang Programming Languages — Informit [Archivado]
Understanding the node.js event loop — Mixu's Blog